
Benchmark性能评估
应用介绍
–OS:Red Hat 7.5
–Driver: MLNX_OFED 4.4.1–
Compilers:Intel compilers 2018.3.222
–MPI:HPC-X v2.2
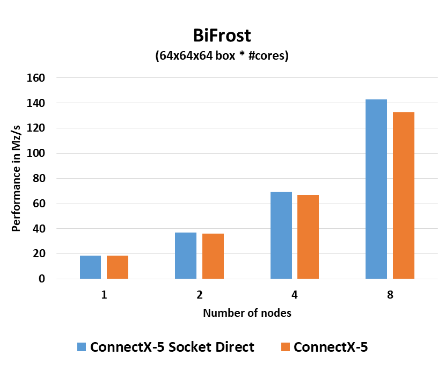
–Application Version: BiFrostv1.1
–Test case:CFD on 64x64x64 box/core
–IO Type:Lustre
–Metric:Application
-reported elapsed time, Mz/s
mpirun-np 512 -bind-to core -report-bindings -mcacoll_hcoll_enable0 -x UCX_MAX_EAGER_LANES=2 -x UCX_MAX_RNDV_LANES=2 -x UCX_NET_DEVICES=mlx5_2:1,mlx5_4:1 -mcabtl_openib_if_includemlx5_2:1,mlx5_4:1 -x MALLOC_MMAP_MAX_=0 -x MALLOC_TRIM_THRESHOLD_=-1 ~/Bifrost_bench_v1.1/RUNS/photo_tr.x.hpcx-2.2.0
©版权声明:本文内容由互联网用户自发贡献,版权归原创作者所有,本站不拥有所有权,也不承担相关法律责任。如果您发现本站中有涉嫌抄袭的内容,欢迎发送邮件至: www_apollocode_net@163.com 进行举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。
转载请注明出处: apollocode » Benchmark性能评估
文件列表(部分)
| 名称 | 大小 | 修改日期 |
|---|---|---|
| BiFrost_AMD_Aug2018(1).pdf | 397.88 KB | 2020-05-27 |

发表评论 取消回复